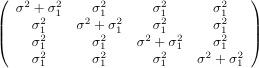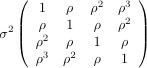In a test of how well people remember instructional materials, subjects of various educational levels were presented with training materials that were either in Black & White or in Colour. Their ability to recall the material was tested with both Cartoon and Realistic testing materials at two points in time -- immediately after training, and several weeks later. Scores on an IQ test (the Otis Mental Ability Test) were available for all subjects. The variables are
- Subject identification number
- Colour of training materials: 0 = Black & White, 1 = Colour
- Education: 0 = Pre-professional, 1 = Professional, 2 = Student.
- Location: 1 = Hospital A, 2 = Hospital B, 3 = Hospital C, 4 = Penn State University.
- Otis Test of Mental Ability (IQ)
- Recall at Time One, Cartoon testing materials
- Recall at Time One, Realistic testing materials
- Recall at Time Two, Cartoon testing materials
- Recall at Time Two, Realistic testing materials
The data are available in the file
cartoon.data.txt. This is a Minitab data set.
We will teat this as a four-factor analysis of variance, ignoring the other variables.
Please use the "multivariate" approach to repeated measures. That is, you will be using
proc reg or proc glm, not proc mixed.
The factors are Colour of training materials, Eduction, Time (One versus Two), and Testing materials (Cartoon versus realistic). Take a look at the raw data. See all the missing values? This does not make us feel comfortable, but we will proceed anyway and analyze the cases with no missing data. It's helpful to completely exclude cases with any missing data. A search on SAS subset if will show you an easy way to do this.
- Classify the factors as within-cases or between-cases.
- Carry out the analysis, obtaining tests of all the main effects and interactions. How many tests are you doing? Be ready with all the F statistics and p-values.Remember, if you give
proc reg a list of response variables, you get univariate output for each response variable. The results of test statements come in a particularly handy format. These results are a relief. They will be easy to talk about.
- Carry out Bonferroni-corrected pairwise comparisons of the marginal means for education. This is a family of just three tests. In plain, non-statistical language, what do you conclude? I did this by running proc glm on my sum variable and using
lsmeans.
- Sticking strictly to the 0.05 significance level, did you get any significant interactions? Answer Yes or No. If Yes, which ones were significant?
- For each of the significant main effects, describe the resullts in plain, non-statistical language. You don't have to say "averaging across other factors" or anything. Just say what happened.
Bring your log file and results file to the quiz.